Primeiro Nível de Avaliação – Estrela
Na dimensão da Focalização no Utente apenas serão divulgados ratings para os prestadores que, cumulativamente, cumpram com os seguintes critérios:
-
Tenham preenchido integralmente e submetido a check-list base para avaliação da Focalização no Utente;
-
Estejam em cumprimento com todos os “pontos críticos” dessa check-list.
A validação desse cumprimento, demonstrada através da atribuição da Estrela, permite aos prestadores o acesso ao segundo nível de avaliação.
Segundo Nível de Avaliação – Rating
A check-list que serve de base à avaliação da dimensão Focalização no Utente no âmbito do SINAS@Hospitais foi desenvolvida com base num aprofundado estudo de standards e modelos de avaliação de várias agências a nível internacional. Apresenta-se em seguida a metodologia utilizada para a análise estatística da informação recolhida com a check-list.
Modelo de análise estatística
A partir do levantamento de informação suportado na check-list, procede-se ao cálculo de um rácio de cumprimento de procedimentos de focalização. Este rácio é um indicador de estrutura que corresponde ao número de condições verificadas sobre o número de condições exigíveis. As condições exigíveis correspondem a todos os requisitos em que não foi respondido N/A (não aplicável). Note-se que essa opção de resposta não é admissível em todos os requisitos.
Na imagem seguinte apresenta-se a forma de cálculo do rácio de cumprimento.

Após o cálculo dos rácios de cumprimento para todos os prestadores, obtemos uma lista ordenada de prestadores, cujas diferenças são analisadas qualitativamente com recurso a uma metodologia de clustering.
O clustering permite a partição de uma lista ordenada de observações para construção de grupos de observações com maior afinidade. No âmbito do modelo aqui exposto, o clustering resulta no agrupamento de prestadores segundo o critério de proximidade em termos do indicador de performance (o rácio composto), maximizando o grau de associação entre observações do mesmo grupo e minimizando o grau de associação entre observações de grupos diferentes.
Das diversas técnicas de clustering existentes, foi utilizada a técnica das k-means, considerada a mais adequada para estudos em que temos, à partida, uma hipótese quanto ao número de grupos a formar. O essencial desta técnica apresenta-se na imagem abaixo.

O procedimento de k-means é executado através de um algoritmo composto por passos que são iterados até ao ponto de convergência em que se obtém uma solução (distribuição de prestadores por clusters) que não sofre alterações relevantes nas seguintes repetições do algoritmo.
O algoritmo concreto que aqui é utilizado é o proposto por Hartigan e Wong. Simplificadamente, inicia-se o procedimento com k médias aleatórias, seguidamente adicionando-se todos os pontos da distribuição à média mais próxima para formar k grupos de pontos. Cada vez que um ponto é adicionado a um grupo, a média do grupo é ajustada tendo em conta esse novo ponto, resultando num novo conjunto de k médias. Estas novas médias são agora utilizadas para a distribuição de todos os pontos em k grupos, da mesma forma que foi descrita. Estes passos são repetidos até que as médias dos grupos não sofrem alterações significativas nas sucessivas repetições.
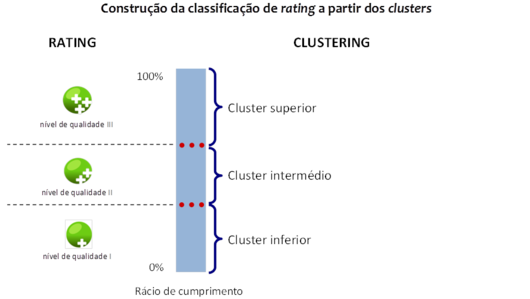
Produção de rating
A atribuição de ratings é realizada através da classificação dos prestadores em três clusters, de acordo com os grupos de prestadores criados naturalmente pelo algoritmo:
- prestadores com rácio de cumprimento no cluster superior são classificados com “nível de qualidade III”;
- prestadores com rácio de cumprimento no cluster intermédio são classificados com “nível de qualidade II”; e
- prestadores com rácio de cumprimento no cluster inferior são classificados com “nível de qualidade I”.
A figura seguinte apresenta uma explicação visual da lógica de construção do rating.